
写在前面:如果您还不知道anaconda是什么,或者不知道如何创建/激活环境,请移步至本专栏第一篇文章查看
在本篇文章中,我们来看一个机器学习的 真·入门级 案例:Titanic – Machine Learning from Disaster,题源为kaggle,其简介内容如下:
泰坦尼克号的沉没是历史上最臭名昭著的沉船事件之一。
1912 年 4 月 15 日,在她的处女航中,被广泛认为“永不沉没”的 RMS 泰坦尼克号在与冰山相撞后沉没。不幸的是,船上的每个人都没有足够的救生艇,导致 1502 名乘客和船员中有 2224 人死亡。
虽然生存下来有一些运气因素,但似乎某些群体比其他人更有可能生存下来。
在本次挑战赛中,我们要求您构建一个预测模型,使用乘客数据(即姓名、年龄、性别、社会经济阶层等)回答“什么样的人更有可能生存”这个问题。
在本案例中,你将学习到:
- 使用pandas对数据进行基本的加载、筛选
- 使用scikit-learn提供的机器学习模型–随机森林模型进行数据的训练与预测
step 1: 安装python库:scikit-learn
首先,请以管理员权限运行 anaconda prompt 并在其中激活您的python虚拟环境,然后输入:conda install scikit-learn
此后,输入“y”确定以开始下载,等待下载完成。
step 2: 导入数据,并对数据做一些简单的预处理
本处博主选择使用jupyter工具来完成本项目,如果你也想使用本工具,请在您的项目文件夹激活cmd终端,并在终端激活您的python环境,此后在终端输入:jupyter lab,如果您比较熟悉jupyter notebook,您也可以将其替换成notebook
项目文件夹结构:
fuxian_titanic/
│
├── titanic/ # Titanic项目相关文件夹
└── Untitled.ipynb # Jupyter Notebook源文件
首先导入需要的库文件:
import pandas as pd
import os
from sklearn.ensemble import RandomForestClassifier
读入训练集数据:
train_data = pd.read_csv("./titanic/train.csv")
此后,您可以使用train_data.head()查看train_data中的前5条数据:
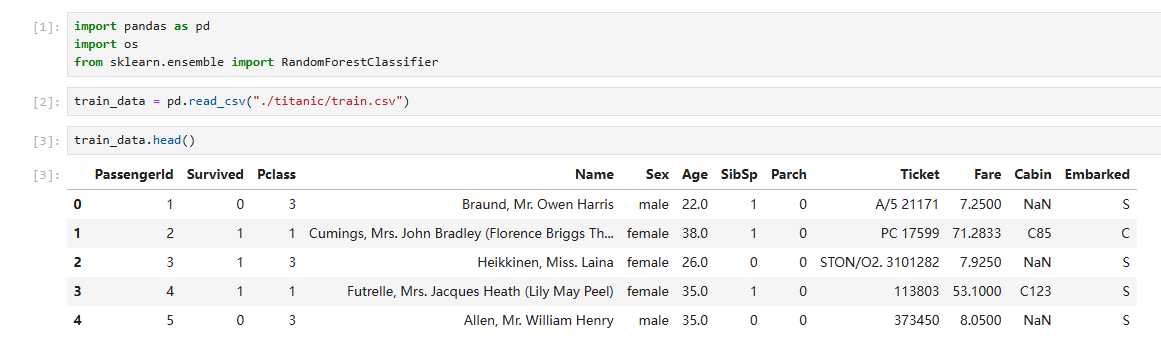
您可以以同样的方式查看test_data中的数据
在这里,我们可以学习使用loc函数来计算训练集中性别的不同对生还率的影响,例如我们计算女性在这场灾难中的生还率:
# 我们已经在前面导入了训练集数据train_data
# 使用loc函数筛选出满足条件“train_data.Sex == 'female'”的数据之后,再从这部分数据中取出表头(标签)为Survived的数据,该部分数据以0/1记录对应PassengerId的生还与否,其中1表示生还
# loc函数的作用就是根据设定的bool条件筛选数据
women = train_data.loc[train_data.Sex == 'female']['Survived']
# 0 或者 1 表示乘客未获救或者获救,其中sum的值求出的是所有1的和,即表示获救的人数
rate_women = sum(women) / len(women)
同理,我们也可以依次筛选出反方向的数据,例如“生还的乘客中,标签为male的生还率”、“标签为male的死亡率”、“标签为female的死亡率”等等,本部分内容请读者自行实验
您愿意动手的对吧?

step 3: 初始化机器学习模型,开始训练
在机器学习中,训练集最重要的无非两部分:数据和数据对应的标签
那本文案例中,标签应该是什么呢?
本案例要求您构建一个预测模型,使用乘客数据(即姓名、年龄、性别、社会经济阶层等)回答“什么样的人更有可能生存”这个问题。
因此,本案例的标签因该是是否生还,对应数据集中应该是 Survived ,因此我们应该初始化标签flag为:
flag = train_data["Survived"]
由于本案例只需要探究“姓名、年龄、性别、社会经济阶层”这四个标签对生还率的影响,因此我们只需要将这部分数据提取出来作为训练集即可,方法如下:
features = ["Pclass", "Sex", "SibSp", "Parch"]
# get_dummies是 Pandas 提供的独热编码函数,会将所有分类型变量(Categorical)自动转换为虚拟变量(Dummy Variables),每个分类值的不同类别会被扩展为一个新的二进制列(0 或 1),原始列会被删除。数值型变量不会被处理,直接保留原值
train_ = pd.get_dummies(train_data[features])
仿照上面的方法,我们可以提取测试集文件中对应的数据:
test_ = pd.get_dummies(test_data[features])
接下来我们借助于随即森林模型作为本文案例的机器学习模型:
# 初始化模型
model = RandomForestClassifier(
n_estimators = 100, # 决策树的数量
max_depth = 5, # 决策树的深度(树高)
random_state = 1 # 随机种子,以便实验的可复现性
)
# fit函数是模型提供的通用的模型训练方法,直接对数据进行拟合,其参数传递为:特征,标签
model.fit(
train_,
flag
)
现在,运行代码就可以实现对模型的训练了!
step 4: 测试模型
类似于fit函数,机器学习模型也提供了快捷的模型测试函数: predict() ,其接收一个参数:测试集数据集,返回一个预测结果
根据上面初始过的测试集test_,我们将其传入函数中,得到的即为传入数据的预测,由于给定的数据为csv文件,因此我们在最后也选择对其进行保存为csv文件,便于提交网站测试
predictions = model.predict(x_test) # 传入测试集数据,返回预测结果
output = pd.DataFrame({ # 设置保存csv文件的一些格式,例如列名
"PassengerId": test_data.PassengerId,
"Survived": predictions
})
output.to_csv("submission.csv", index=False) # 保存为csv文件
到这里,本文案例就到达了尾声了,恭喜你成功完成了本文的案例!将最终保存的csv文件提交官网检测,得到反馈结果如下:

在最终的提交结果中,我们可以看到准确率在77.5%,这说明什么呢?如果希望提高准确率的话,我们又应该从哪些方面入手呢?请读者思考这两个问题。
如果您在阅读本文的过程中有所收获,或者有任何宝贵的建议和想法,欢迎通过邮箱或是微信等方式给我留言交流,您的每一次建议都将是我前进的动力!在此,博主斗胆向您提出一个小小的请求,如果您觉得本文给您带来了一丝启发,不妨动动手指,给予一点点鼓励。万水千山总是情,您的打赏,哪怕只是 0.1 元,也是对博主莫大的支持!(悄悄告诉您,博主正在为服务器众筹中 (×﹏×),您的每一份心意都将助力博主走得更远!)感谢您的慷慨,愿我们的缘分如同这网络世界,绵长不断


